本記事は 画像生成AI Advent Calendar 2022 の19日目です。
Needleと申します。2013年からVRにハマり、2014年から2018年までOculus日本チームに在籍した後、現在はフリーランスでVR開発の各種支援を行っています。
上記のようにVR歴はそこそこ長いのですが、現在のVRの使い道の主流のひとつであるVRChat文化には、長らく乗っかれていませんでした。というのも、どうにも自分の中で利用に至るまでの心理的なハードルがあったからです…(しばらくAIに直接関係ない話が続きます。クソ長自分語り注意)。
背景(自分語り)
アバター文化に乗れない。
…どうも自分がアニメ調美少女になる気が起きない。別にアニメ絵自体は嫌いではないのですが。
「みんな最初はそう言うんですよ」と言われてもなる気が起きないものは起きず、何を試着してみても強烈な「自分じゃない」感が拭えません。それ以外のアバターも豊富に存在はするものの、服を買いに行く服がない状態ですし、アバターミュージアムやバーチャルマーケット等のアバター展示を巡ってみてもどうにもしっくり来ません。そもそもTwitterですら日本の多数派の匿名・非実写アイコンな使い方ではなく、実名を隠さず実写アイコンで長年使っていたので、今から顔や名前を隠して1からペルソナを作るのも今更感が。
現実でも自分の外見にはあまり興味を持っているほうではないのですが、現実ではどれほど外見に興味がなくて化粧や肉体改造といった外見に関する選択や操作を何も行わなかったとしても、生得的に自分の身体や外見が「ただそこにあり」ます。一方、ソーシャルVRにおけるアバターでは、外見を選ぶことが可能であるのみならず、明確な意図を持って選ぶことを事実上強制されるとも言えます。
「やった!これまでの人生のアイデンティティから離れて自由に選べる!」と解き放たれたように感じる人には素晴らしい事なのですが、自分の場合「選べと言われても…『選ばない』っていう選択肢は無いんですか?」という感想になってしまいます。(その点ではclusterは有難いなと思っています。最初の頃はアバターが全て無個性なロボットで統一されており、後からVRM形式モデルの読み込みに対応したという経緯があるため、無個性ロボを選ぶ事である程度「選ばない」をさせてもらえます)
一方VRChatでは、アバター非表示設定時等に使われるシンプルなロボットアバターは一応存在するものの、「選ばない」事は事実上出来ません。せっかくVR界隈に身を置いているし、という事で今年の半ばあたりから意識的にVRChatを使ってみるようにしていたのですが、この時最初は前述のロボットアバターをわざと使っていました。しかしこの格好でいると「アバター選ぶの手伝いましょうか?」「ロボットになってますよ、設定合ってますか?」と親切な人が寄ってきてしまっていたたまれなくなるため(まさか好き好んで使ってるだなんて思わないのでしょう)、別の無個性なアバターをわざわざ探す羽目になりました。
なお、正確には「無個性にしたい」のではなくて「『選ばない』をしたい」なのですが、それは出来ないのでせめてなるべく無味乾燥なものを求める形になっています。もちろん、美少女アバターユーザーが沢山いるVRChatで敢えて使う人の少ない無個性ロボを選ぶのは逆に悪目立ちするのですが、それでも。
これはVRじゃなくて画像生成AIのアドベントカレンダー記事だって?
はいそうでした。ちゃんと繋がりますので。
生成的AIの話題は、DALL-E 2やMidjourneyやDALL-E Mini(現Craiyon)が使えるようになった頃から徐々に凄いらしいという話が聞こえてきていましたが、Stable Diffusion (以下SD) の登場は衝撃でした。DALL-EにせよMidjourneyにせよ、実際の処理はWebサイトやAPI越しにどこか遠くの預かり知らぬ所にある雲の中で実行されて、自分のデバイスにはその結果が送られてくるだけでしたが、SDは手元のPCで!ローカルに!実行できます。一度インストールしてしまえばサーバーへの接続は不要です。電気さえあれば、プロバイダーの回線が落ちようが海底ケーブルが破断しようがGAFAMのデータセンターが全部爆発しようが動きます。昔PhotoshopやDOOMを初めてインストールした時に感じたような、「自分のPCが魔法の箱になった」と言う感覚を久々に味わう事になりました。
自分のPCは機械学習でデファクトスタンダードの地位にあるNVIDIAではなくAMD製のグラフィックカードを搭載していたため、最初に動かせるまでしばらく手こずりましたが、ひとたび動き出した後は使い放題なのを良いことに夢中で生成をぶん回しまくっていました。ガチャのような中毒性があります。
界隈の技術開発の速度がとんでもなく速いのも魅力です。最初こそコマンドラインを叩いてましたが、すぐにAUTOMATIC1111やNMKDのユーザーインターフェイスが作られ、Textual InversionやDreamboothなどモデルの追加学習手法が登場し、あの手この手で消費VRAM量や生成速度が改善され…。「日刊 画像生成AI」が無いとついていけない速さで、毎日更新されているやまかずさんには頭が上がりません。
DreamFusionの登場
そんな中、DreamFusionというText-to-3Dを実現する論文がGoogleにより発表されました。SDはプロンプト文字列から画像を生成するものでしたが、これは何と3Dモデルをメッシュとテクスチャ揃えて生成するという代物です。興味深いのは、既存の画像生成AIを活用して3Dモデルを生成するため、大量の3Dモデルデータを学習する必要が無いという点です。DreamFusionはGoogle内製・非公開の画像生成AIであるImagenの上に構築されたため、コードが一般公開されていません。しかし、論文の発表からものの一週間ほどで、論文の内容をベースにStable Diffusion上で動作するようにしたStable-DreamFusionという実装が有志により開発・公開されました。速すぎる。
ここで思いました。アバター作れるんじゃね?
前述の「外見を選びたくない」という問題の解決は置いておくにしても、作れそうと思うとやってみたくなります。
アバター自動生成
2Dラフの生成
3Dの生成は2D画像よりもはるかに時間がかかるため、まずは2Dでおおまかなイメージを考えます。試した当時のStable-DreamFusionは素のStable Diffusion 1.4決め打ちで書かれていたため、アニメ調よりは実写調に近い方で狙います。また、3D生成はまだ精度が高くないため、多少崩れてもおかしく見えにくいロボットをモチーフにしてみます。
手元のPCにインストールしてあるAUTOMATIC1111版GUIを使い、プロンプトを調整しながらたくさん生成してそれっぽいのを探します。なるべく画角中央に、はみ出さずに、Tポーズで立っていてほしいので、そうなるようにプロンプトを書き換えていきます。
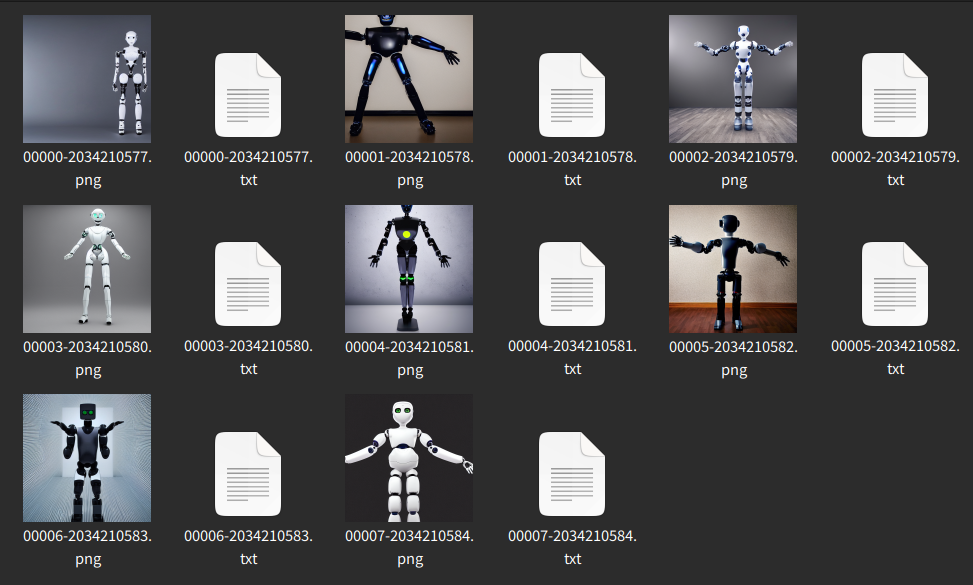

プロンプトと絵のおおまかな感じが掴めたので、良さげなもののプロンプトとシード値をメモって3Dに行ってみます。(画像の縦横サイズが変わっただけでも絵は大きく変わるので、同じシード値を使うことにどれだけ意味があるかはわかりませんが。)
Stable-DreamFusionモデル生成
Stable-DreamFusionはRadeonでは動かなかったため、NVIDIA GPUをWeb越しにレンタルできるGoogle Colabを使います。Stable-DreamFusionのノートブックを開き、基本的には上から順番に実行ボタンを押していきますが、プロンプト内容やTraining_itersはフォーム上の値を適宜書き換えたうえで実行ボタンを押して反映させます。
Colab ProのNVIDIA A100 (VRAM 40GB)で処理を回す事40分、こんな結果が出てきました。
Stable-DreamFusionのコマンドラインオプションにはネガティブ指定機能が見当たらなかったため、ネガティブプロンプトは無し。
思った以上にちゃんと人の形をしています!顔にあたる部分もよく見ると眼窩のようなへこみが2つ見られます。ただし、腕と足がそれぞれ3本ずつ出来てしまっています。これはJanus問題と言われ、ローマ神話のヤヌスのように頭に顔が2つついてしまったり、今回のように手足が増えてしまったりするDreamFusionの既知の問題です。せっかく生成されたものなのでそのままで残しておこうかとも思いましたが、アバターを自分で動かすときに3本目の手足は何によって動かされるべきなのか…?というのが不明なため、仕方なく切り落とす事にします。
生成後の手作業整備
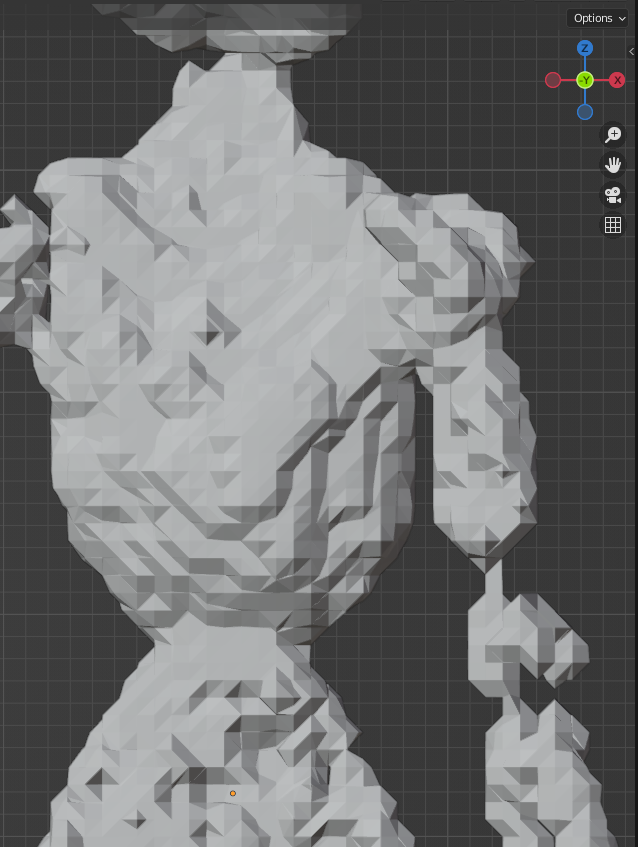
まともにBlenderを使うのは初めてですが、生成されたモデルのobjファイルを読み込み、アバターとして使えるようにいくつか整備します。前述の3本目の腕と足を切り落とし、残った2つの足も左右が癒着してしまっているため切り離します。また、後述する自動リギングを行う際にポリゴンが離れていると一連のつながった腕として認識されないため、左右の腕の関節の浮いている箇所を繋ぎます。(この画像は腕の関節を連結させた後のものです。)
一通り整備した後、BlenderからFBX形式で出力します。いずれはこういった手作業が不要なクオリティで出力される日が来るといいのですが。
Mixamoによる自動リギング
アバターのリギングはAdobe Mixamoを使って自動で行います。読み込んだモデルの位置を微調整し、手先・関節などにあたるべき部分の点をマウスでドラッグして指定します。最初に試した時は腕の関節と腕の他の部分が離れていたためエラーが起きましたが、腕を連結させたら正しく認識されました。これによりリギング済みのFBXファイルがダウンロードできます。なお、指は5本しっかり作られていないので、手や指のボーン構造は簡易的なもので済ませます。例によって「AIは手が苦手」はここでも健在です。
VRChatアバターとして読み込み
VRChat Creator Companionから新しいアバタープロジェクトを作成してUnityで開き、リギング済みのFBXファイルを読み込みます。自作アバターは初めてなので凝ったギミックなどは入れず、解説記事を参考にしながらサイズ設定・ボーン構造の差異の修正・視点位置設定・マテリアル設定・メタデータ記入などを行います。日本人VRChatユーザーのアバターは身長が低めな事が多いので、それに合わせて身長130-140cm位に設定しました。全部整ったら最後にアップロード。



VRChatを起動して、PCに繋いだMeta Questをかぶり、アバターを適用。自分の手を見ると青いアバターの手が見えます。
鏡の前に行って体を動かすと、ちゃんと動いてます、成功です!
なぜか生成時点では白っぽかったテクスチャ(これも自動生成です)が全体的に青っぽくなっていますが、なぜこうなったのかはよくわかっていません。しかし靴のような部分は白、関節部分は黒など、部位に応じた色分けは特に指定しなくてもちゃんとされているようです。
このアバターを10月上旬に作って以来、しばらくこれを使い続けていますが、見た目の印象が珍しいからか、時々声をかけられます。AI自動生成だという事を明かすと興味を持ってもらえるし、初対面の人との話のネタにもなっています。これは「外見を選択しない」なのか?と言われるとそうではないですし、じゃあ果たしてこれは「自分」なのか?というと結局確固とした答えは出ていないままなのですが、少なくとも前よりは違和感を纏ったままVR内をうろついている感覚が減ったのは確かです。イケア効果でしょうか…。
その後やった事いろいろ

- 「建造物も作れるのでは?」と考え、ガゼボ(公園にあるような東屋の西洋版)のモデルを生成。点対称な形状だとJanus問題の影響を受けないので楽です。なお、1回目は屋根の下が詰まった状態で生成されてしまったので失敗して、これは2回目の生成。


- VRChat SDKでワールド用プロジェクトを作り、ガゼボを置いた簡単なワールドを作ってCommunity Labsにアップロードしてみる。VRChatがインストール済みの人はこちらのリンクから訪れることが可能です。
- なお、地面の草のテクスチャもSDによる自動生成です。AUTOMATIC1111版GUIは縦横タイリングできる画像を作る機能があるのでそれを使いました。
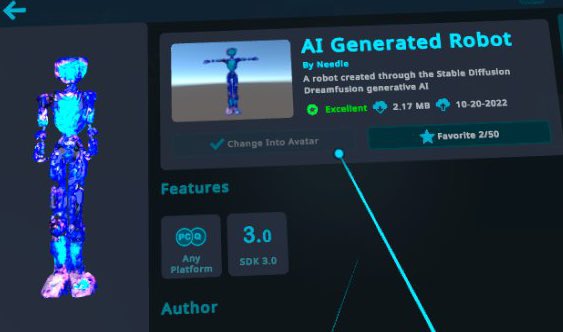
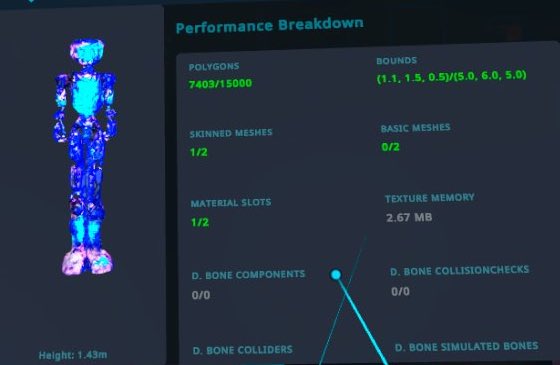
- 作ったアバターはDreamFusionから出力された素の状態では38,000ポリゴンほど。PCアバターとしてはGood判定となるものの、Questアバターとしては重いので、BlenderでデシメートしてQuest版アバターを作り、約7,400ポリゴンまで削ってQuest Excellent判定をゲット。単純にBlenderの内蔵機能でデシメートしてるだけで、普通のアバターなら露骨にガビガビになりそうですが、まあ元からカクカクしてるので気にしない気にしない。
おわりに
今回作ったアバターは抽象的で、モデルとしての質も高くなく、様々な手作業を挟む必要がありました。しかし最近ではDreamFusion以外にも、NVIDIAのGet3DやMagic3D、Luma AIのImagine 3D、ほかLatent-NeRFなどなどText-to-3Dを目的とした様々なAIモデルが登場してきました。綺麗なキャラクターのアバターが半自動〜全自動で生成できるようになる日も、もしかしたら遠くないかもしれません。
なお、僕のVRChat IDはNeedleです。見かけたら遊んでください。